【AIによる音声認識の活用事例】音声認識で無くなる手間と障壁

音声認識とは?その原理について

音声認識とは、音声を聞き取り、コンピュータを通して認識(データ化)することを指します。私たちが、「おはよう」と発したら、コンピュータ上で「おはよう」と認識する技術です。身近なものだと、Amazon社の「Alexa」やApple社の「Siri」が音声認識を用いたものになります。
ではどのように音声を認識しているのか見ていきましょう。
私たちの声(音声)は、次のような手順を通って認識されます。
・音声検出
・音響分析
・音響モデル
・テキスト化
ここでは、音声認識で認識の精度を大きく左右する音響分析と音響モデルについて詳しく解説します。
音響分析(特徴抽出)
音響分析とは、入力された音声などから特徴を見つけ出し、数値化するものを指します。特徴を数値化したものを「特徴量」と言います。
なぜ特徴量を求めるのかというと、次の工程で音響モデルを用いて入力された音声を解析する際に、解析に使用する統計データなどのライブラリが、数値化されたデータしか扱えないからです。
具体的には、音声から音の高さに関する基本周波数1や、音色に関するフォルマント周波数2などの特徴を測定します。
*1基本周波数とは、合成された音の中でもっとも周波数の低いものを指します。例えば、神社で鐘を鳴らした際に「ボーン」と音がなるとします。その音を解析してみると、高い音から低い音まで含まれています。そのうちの一番低い音の周波数を基本周波数といいます。
*2フォルマント周波数とは、音声の中に含まれる周波数の中で、ピーク(波形で見たときに大きな山)がみられる周波数のことを指します。フォルマント周波数は音に特徴をつけるので、AさんとBさんの声が違う音に聞こえるのは、このフォルマント周波数が違うからです。
音響モデル
先ほどの音声分析で特徴量を測定したので、次はその特徴量を過去に収集した音声データなどの統計データを用いて、入力された音声が何かを判別します。
この際に用いられる、大量の特徴量をまとめた統計データのことを音響モデルといいます。
この音響モデルを使い、先ほど測定した特徴量を統計データに照らし合わせ、何と発音していたかを導き出します。
つまり音響モデルは、音声認識の精度を左右する大切なデータです。
音響モデルのデータ数が少なすぎたり、自分が測定したい特徴量にあわない音響モデルを使用すると、欲しいデータが求められなかったり、求められても精度の低いものになってしまいます。
音声認識の歴史と最新の動向について

次は音声認識の歴史と、最新の技術についてみていきましょう。
音声認識は60年以上の歴史を重ねてきている
音声認識は60年以上の歴史があり、その中で以下の約6回変遷期があると言われています。

(引用元:日本音響学会誌第74巻07号(2018) より「音声認識の変遷と最先端」)
第1世代のヒューリスティック方式は、音声タイプライターを代表とします。音声タイプライターの場合では、短音節のみタイプライターで文字起こしができます。
第2世代のテンプレート方式は、DPマッチングを代表とします。DPマッチングとは、特徴量を元々あるテンプレートに重ねて類似度を比較するものです。
音声認識では長年にわたり、第3世代のGMMーHMMという技術が用いられていました。
GMM-HMMとは、統計データに基づいた音声認識で、複雑だったため、あまり一般に普及していませんでした。
それが、2015年にニューラルネットによるEnd-to-Endと呼ばれるモデルになりました。
End-to-Endモデルとは、音響モデルや発音辞書、言語モデルが一つのニューラルネットワークで構成されています。
よって、非常にシンプルな構成になるので、スマホ上で動作が容易に行えます。
新しい技術の登場と応用可能なモデルの増加
音声認識はAIの登場によりさらなる進化を遂げています。
三菱電機は、2019年に「Maisart®︎(マイサート)」を用いて、何語を話すのかわからないユーザが不特定多数いる状況でも高精度な音声認識を実現する「シームレス音声認識」を開発しました。
従来の音声認識技術では、事前に言語の設定を行う必要があります。しかし、この「シームレス音声認識」を用いることで、事前の言語設定なしに、5言語で90%以上、10言語でも80%以上の高い音声認識率を達成しているそうです。
また、googleが「Google Cloud Speech-to-Text 」という、機械学習を活用して音声をテキストに変換するAPIサービスを展開しています。
この「Google Cloud Speech-to-Text」には動画の字幕作成に向いているモデルや、電話での音声に対応したモデルといった、複数のモデルに応じるモデルが登場してきています。
日本語に対応しているモデルはまだ少ないですが、以下に紹介する活用事例内でも活用されている、今注目のAPIです。
関連:【エッジAIの活用事例】AIカメラからFA機器まで市場規模は拡大の一途
企業のビジネスにおける音声認識の活用事例

では、企業ではどのように音声認識を活用しているのか、見ていきましょう。
カルテの自動入力による負担縮減
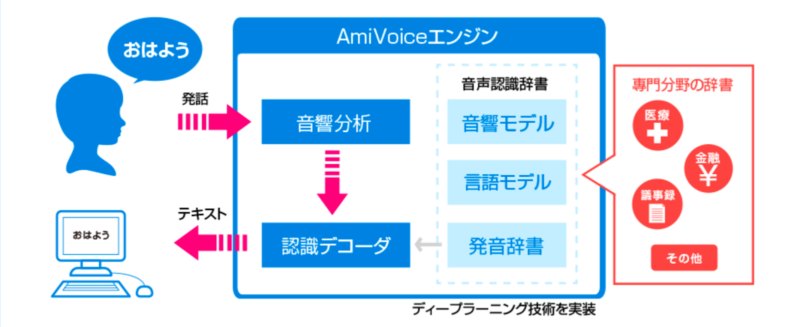
(引用元:株式会社アドバンスド・メディア 音声認識の仕組みより)
課題
医療従事者がパソコン操作に慣れていない等の問題もあり、カルテや紹介状を書く際にどうしても時間がかかってしまい、お客様を待たせてしまうのが課題でした。
解決策
カルテや紹介状などをAmiVoiceを使って音声入力することで、記入の時間を短縮することができます。AmiVoiceは、アドバンスト・メディア社が開発した音声認識です。
このサービスを用いることで、音声入力で簡単にカルテや紹介状など医療記録を取れるのはもちろんのこと、自宅や出張先など、場所を選ばずに効率よく作成することができます。
効果
音声入力だけで作成した服薬指導文の作成スピードが約66%向上しました。
また、患者様の前で紹介状を作成し、その場でのお渡しが可能になったほか、レポートの作成スピードの向上により、1日の読影件数が増加しました。
参考:株式会社アドバンスド・メディア、AmiVoice®︎Ex7
参考:株式会社アドバンスド・メディア、導入事例 医療
会議音声のテキスト化による議事録作成
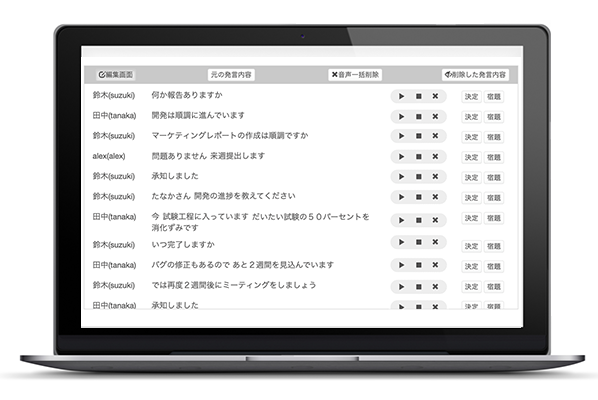
(引用元:NTTCommunications, 議事録作成支援サービス COTOHA Meeting Assist)
課題
会議や講演の議事録を手作業で行っていると、会議や講演以上の時間がかかってしまっていました。
解決策
議事録を取りたい会議でCOTOHAMeetingAssitを用い、会議音声のテキスト化を行います。
期待される効果
COTOHA Meeting Assistを用いることで、議事録作成の時間を短縮して、他の作業時間を大幅に削減することができます。
例えば、その日のうちに議事録をクライアントに送らなくてはいけないときに、COTOHA Meeting Assistを用いて会議を行えば、既に議事録として完成されていて、要点などの確認も容易に行えます。
実際に、会議の時間の倍以上かかっていた議事録作成の作業時間を半分以上に削減した実績も出ています。
(参考:NTTCommunications, 議事録作成支援サービス COTOHA Meeting Assist)
聴覚障がい者に向けたテレビの即時字幕表示
課題
ニュースなどの生放送だと、どうしても字幕を事前につけることができません。そうすると、聴覚障がいを持っている人は映像が流れてから字幕が遅れて表示される形になり、内容が読み取りにくいのが課題でした。
解決策
即時で音声分析をして字幕表示をするツールを導入することで、映像と字幕のズレを縮減します。
効果
この字幕システムによって、聴覚障がいを持っている方だけでなく、電車の中や、お店の中などで音が出せない環境にいる人も、ニュースの内容をリアルタイムで知ることができるようになりました。
現在は、ニュースなど、複数の話者が同時に話さないという良い条件下では、90%以上の正解率を出しているそうです。
参考:ビジネス+IT、テレビ局3社が語る「自動字幕」の裏側 AbemaのAIポンはすでに実用レベル?
まとめ
音声認識により、これからビジネスにおける無駄な時間が削減されていくことが期待されます。
今後音声認識による自動音声によるコールセンターの対応や、製造業の作業者がわからない際に、即座にマニュアルの文を読んでくれると言った技術も広まるでしょう。
また、さらに技術が発展すれば、議事録の作成や文書の作成が翻訳などと組み合わさり、国際的な場などでも活用が進んでいくと考えられます。
今後も音声認識技術の進化による社会の発展に期待がかかります。
実践にいかせるDX人材育成講座をお探しの方へ
DX推進をするにあたり、社内のDXリテラシー教育は避けては通れない道です。
・人材育成はその効果が図りづらく、投資判断がしづらい
・講座を受講させたいが、対象者が忙しく勉強をする時間がとりづらい
などのお悩みを解決する、
受講開始から最短1日で受講完了でき、受講内容を踏まえたアウトプットが得られる「DXリテラシー講座」をご用意しました。
DXリテラシー講座詳細につきましてはダウンロード資料よりご確認ください。
以下リンクよりフォーム入力ですぐにダウンロードいただけます。
また、弊社ではDX/AI人材育成ノウハウや各業界に特化したDX推進事例等をご紹介するセミナーを毎月開催しています。ぜひこちらも貴社のDX推進の一助にお役立てください。

